Dear user,
below you will find a list of screenshots taken from the ProteoSign website, accompanied with a brief description. In some cases, additional helpful information can be found inside the corresponding page. For more details please refer to the article.
The ProteoSign Team.
below you will find a list of screenshots taken from the ProteoSign website, accompanied with a brief description. In some cases, additional helpful information can be found inside the corresponding page. For more details please refer to the article.
The ProteoSign Team.
Welcome page
Basic description of the platform. Clicking the Start button takes the user to the next page.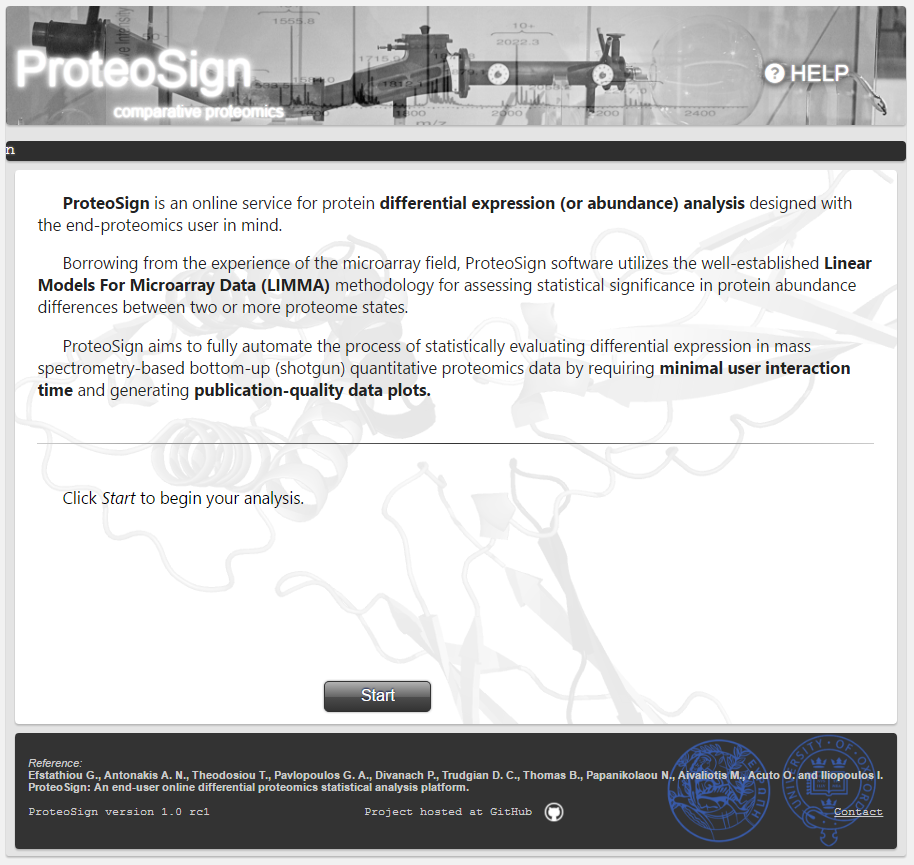
Software input definition page
The first step of any data analysis: defining the input data set. The input can either be uploaded via the Upload file(s) button or, just for demonstration purposes, be selected from pre-uploaded files by clicking the choose hyperlink.
Data file format:
ProteoSign accepts Proteome Discoverer or MaxQuant output data. For the case of MaxQuant, one has to simply upload the automatically generated proteinGroups and evidence output files. For the case of Proteome Discoverer, the output required is a single file, but it is not automatically generated and thus has to be generated by the user. This process is described inside a pop-up dialog which shows up when the user hovers the mouse over the blue-colored question mark. For the sake of completeness, the content of that dialog, i.e. the description of the procedure, is shown below.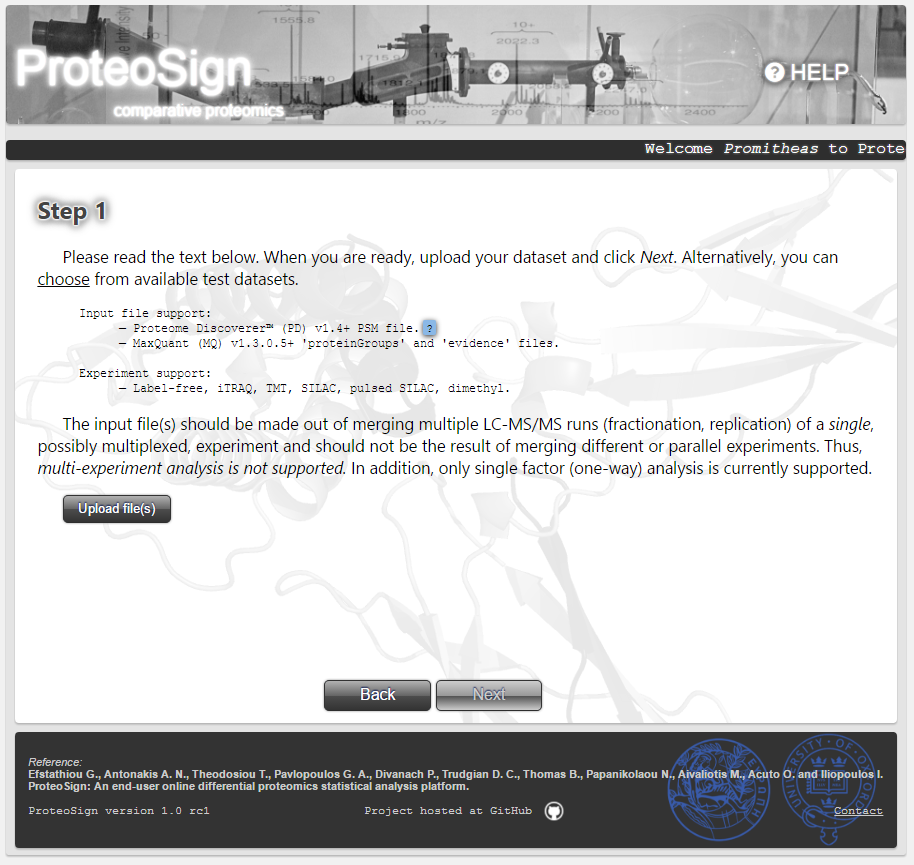
Proteome Discoverer output file generation
The peptide spectrum match (PSM) file, comprising the necessary information required for protein quantitation, has to be produced manually through the PD desktop application (see the Export→To Text option under the File menu).The PSM file must be created from within a PD report which combines the information from all relevant MS analyses (i.e. replicates, conditions etc). Such a PD report is sometimes required to be created based on separate reports and is referred to as a multi-consensus report.
Before exporting the information, one must firstly disable peptide grouping (see relevant screen in Figure 1 on the right) and secondly edit the report's Quantification Method by configuring the Ratio Calculation parameters as shown in the relevant screen in Figure 2 on the right.
-

Figure 1. Disabling peptide grouping. 
Figure 2. Editing ratio calculation parameters. Pre-defined input dialog
By clicking the aforementioned hyperlink choose, a dialog shows up, listing the available demo data sets. The user can select a data set and click OK, as well as, for inspection purposes, download it by clicking Download.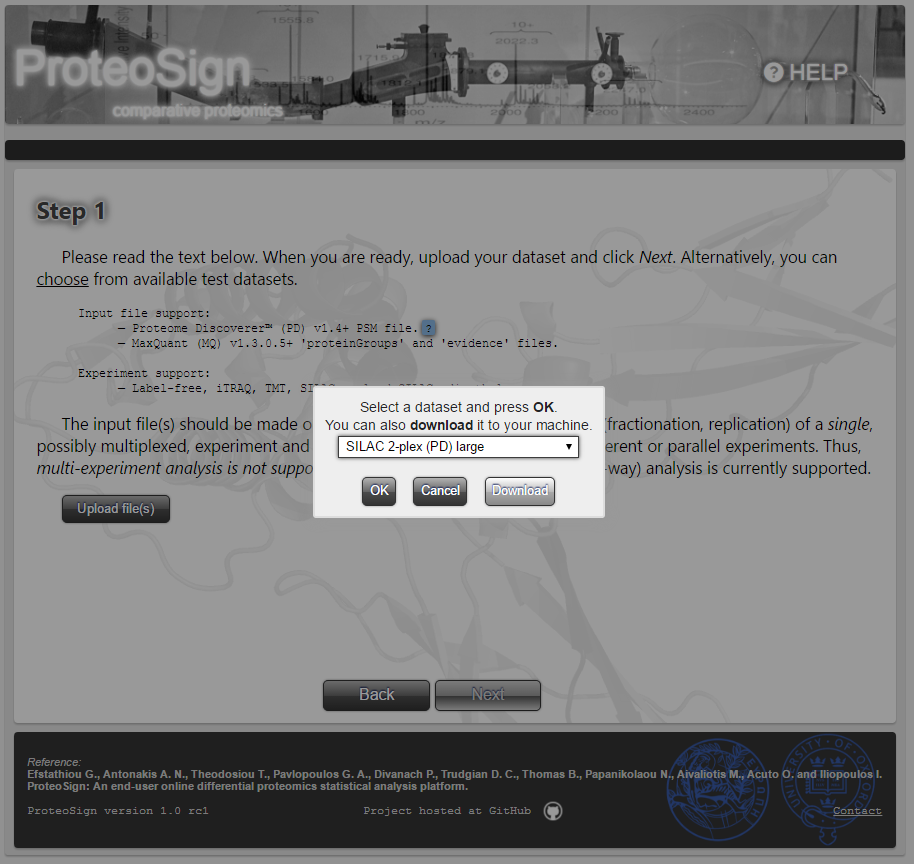
Software input definition page (continued)
Once the input is defined, the software performs a pre-processing step, where the data set is validated. If no error occurs, the user is taken to the next page (see below).
Experimental design definition page
Here the user must define the experimental structure, i.e. which measurements belong to a certain biological or technical replicate. In a biological treatments-multiplexed proteomics experiment, the measurements/data for each biological or technical replicate, or chromatographic fraction, are contained in single raw file.
The table in this page lists the raw files generated in the experiment and the user must assign here the replicate information for every single one of them. In the figure on the right this assignment is automatically performed by the software since a demo data set was selected for analysis.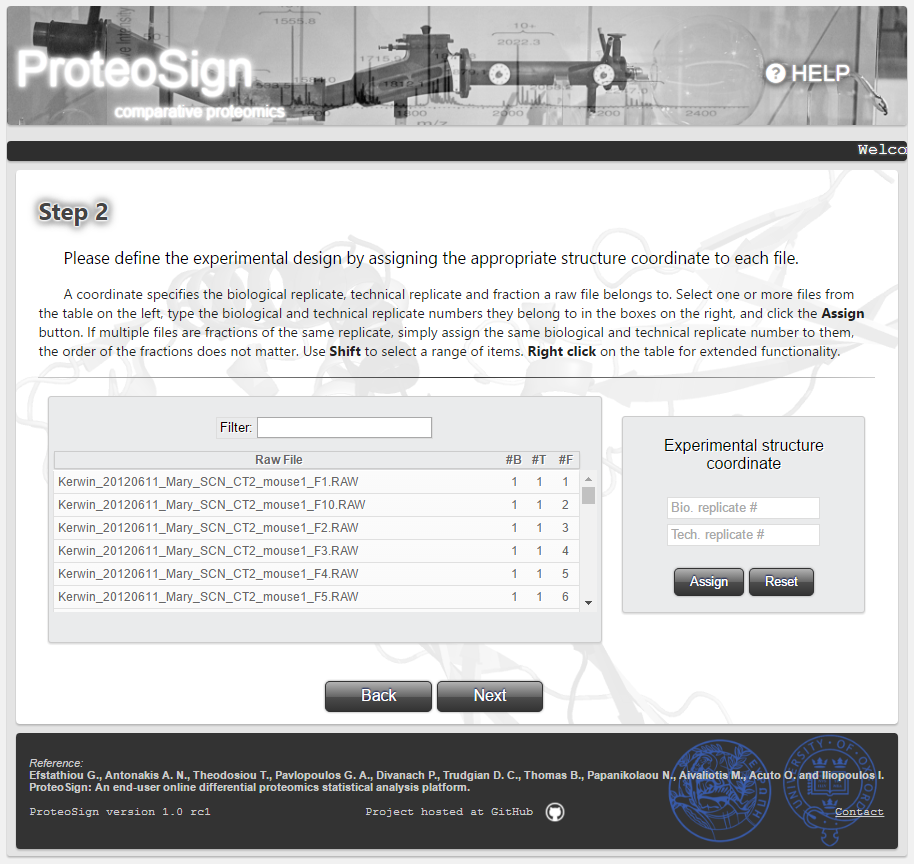
Experimental design definition page (continued)
In the case of user-uploaded data (and not demo data), the figure on the right illustrates the replicate assignment procedure: the user first selects the table rows (i.e. raw files) and then types in the Experimental structure coordinate panel the corresponding biological and/or technical replicate.
Usage note: When multiple raw files are selected, if just the biological replicate is entered, the software will assume that the selected raw files are technical replicates of the entered biological replicate. If both the biological and technical replicates are entered, the software will assume that the selected raw files are fractions of the entered technical replicate.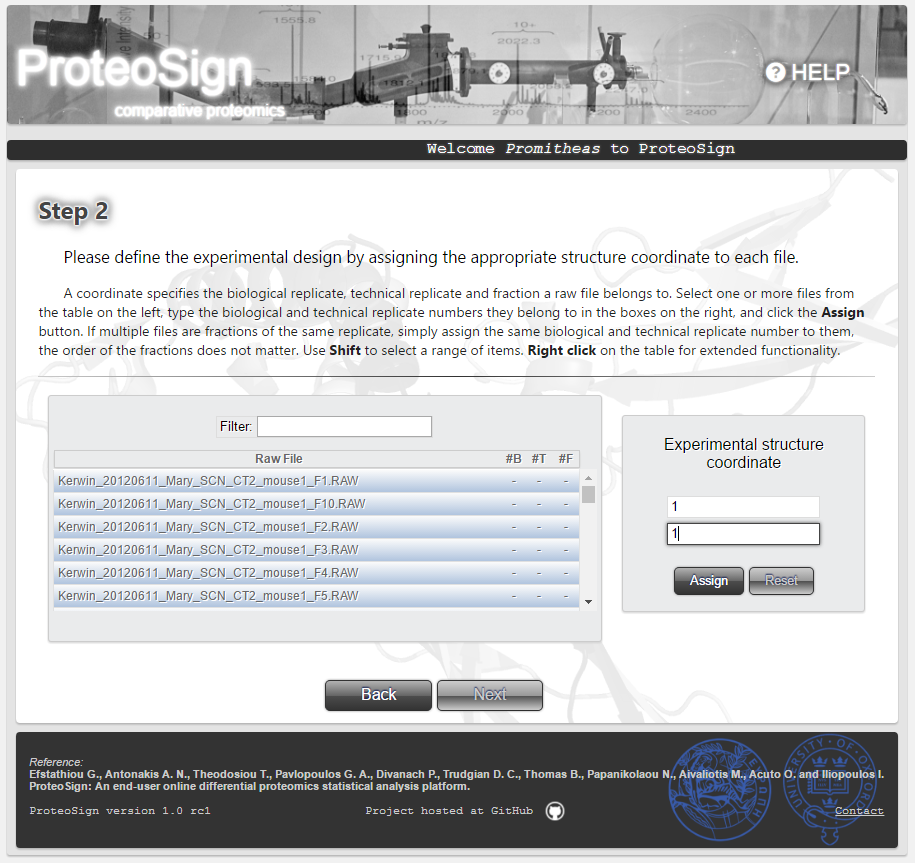
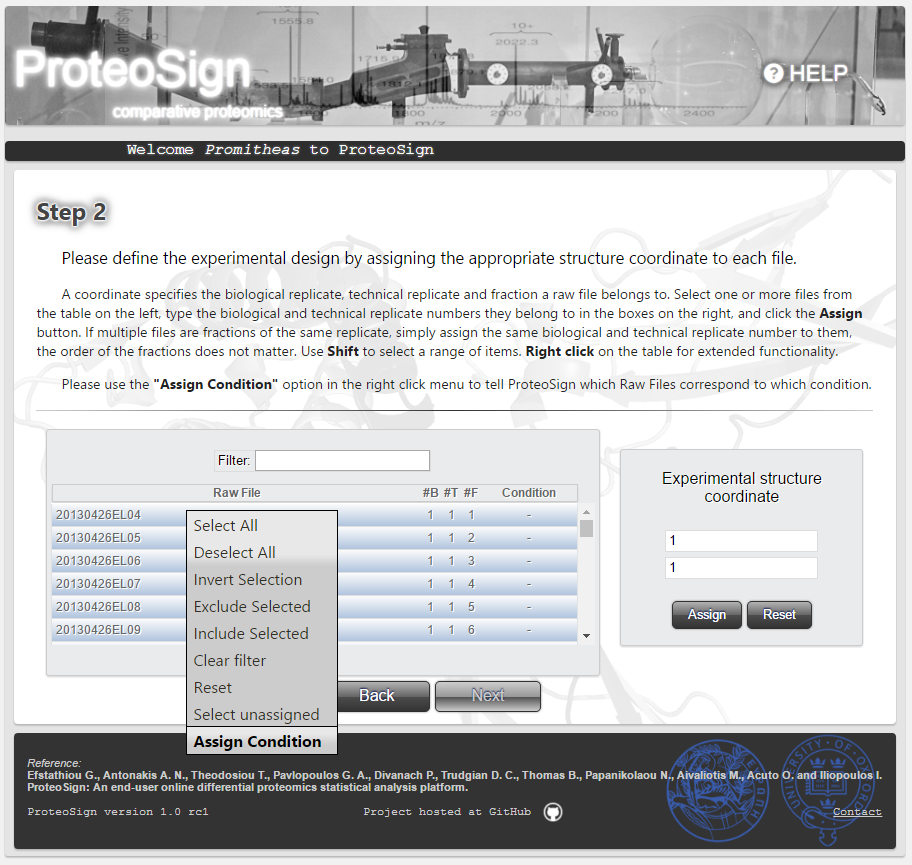
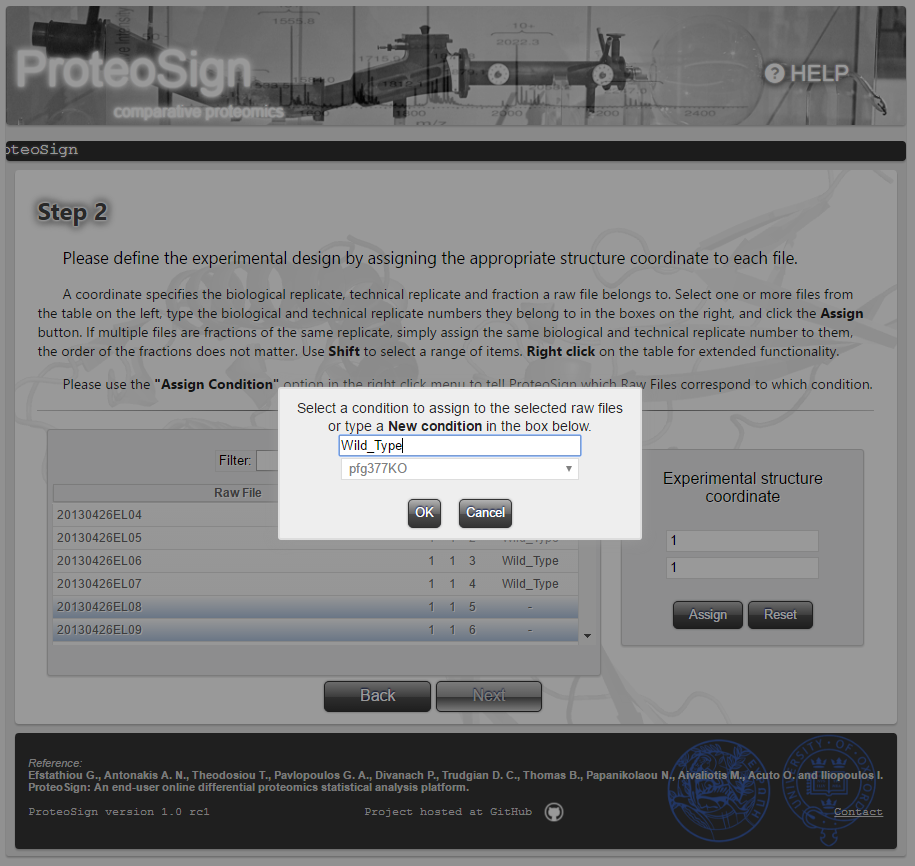
Experimental design definition page (continued): Label-free experiments
In the case of label-free data, the figures on the right illustrate the condition assignment procedure: the user first selects the table rows (i.e. raw files) and by right-click, selects Assign Condition from the popup menu, after which he is asked to either define new condition or choose one defined previously.-
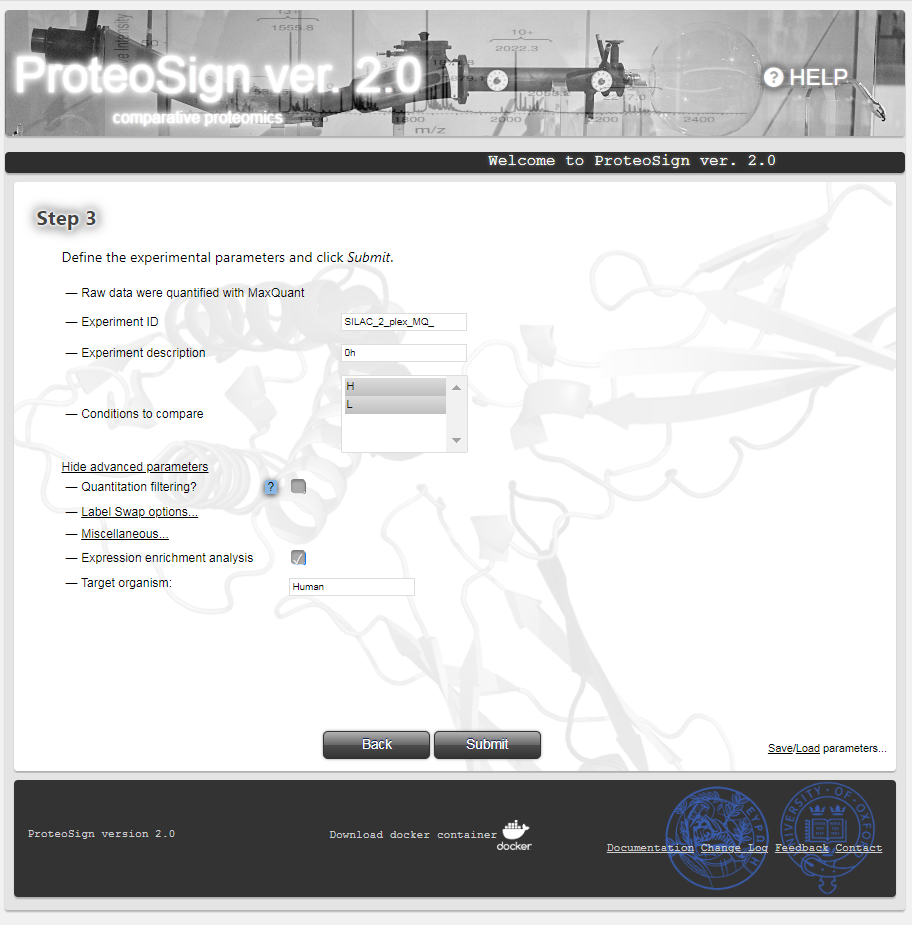
Experimental parameters definition page
Here the user can enter some meta information regarding the experiment (Experiment ID and Experiment description) but most importantly choose the set of biological conditions/treatments to compare against each other. Typically all conditions are selected here via the Conditions to compare list. The advanced parameters section comprises options for filtering-out certain kinds of measurements. More details can be found by hovering the mouse over the question mark icon (at the actual page).
By clicking Submit the user initiates the statistical analysis.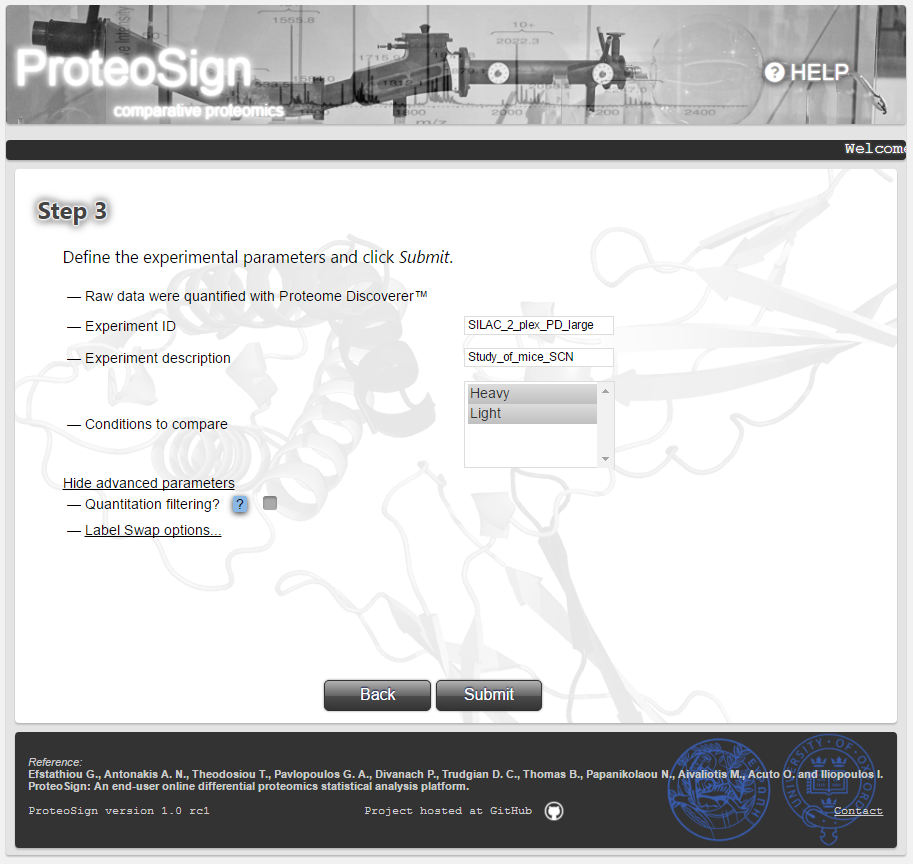
Advanced Options
In case more than one labels was used for the same condition (common in TMT experiments) the user can mark these labels and select Same Condition as illustrated on the picture by right-click. Afterwards, the user is asked to name the respective condition (e.g. Lung_ADC). The conditions that were labelled by more than one labels are always displayed in bold. In order to revert such a condition back to its original labels select Restore Conditions.-
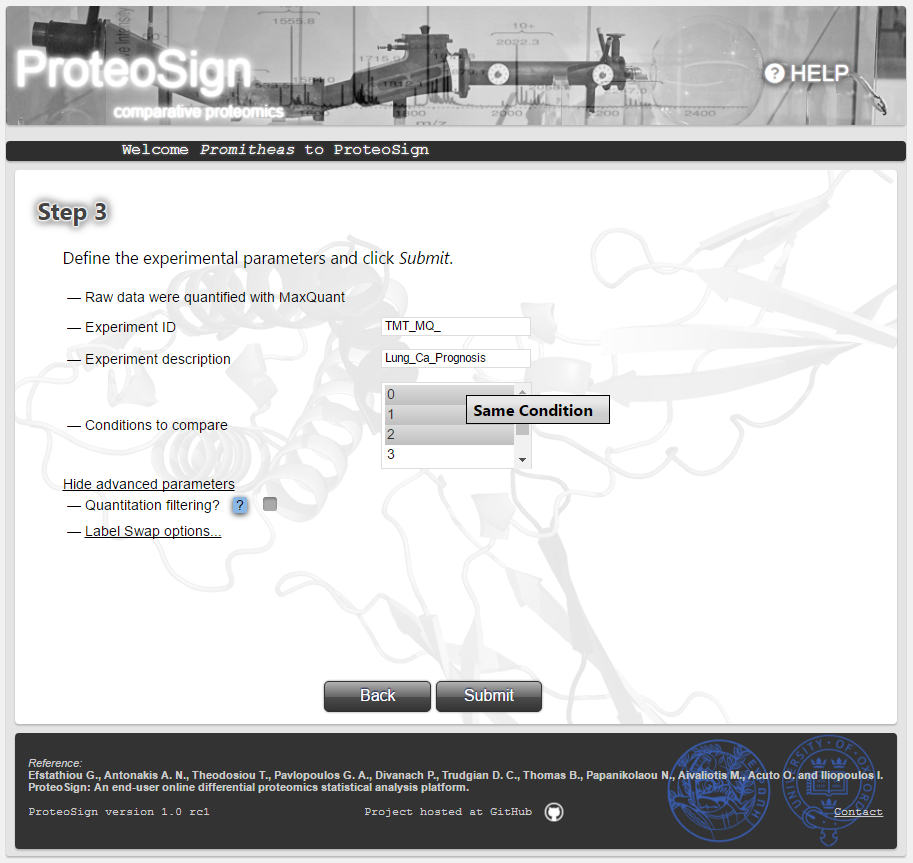
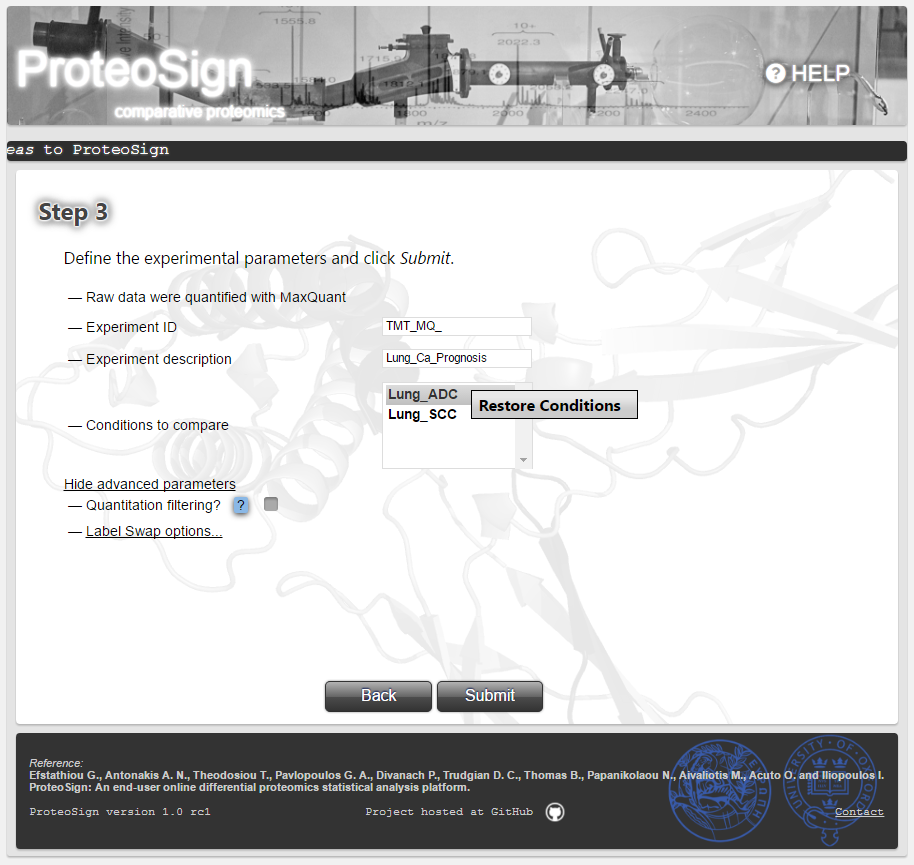
Advanced Options (continued): Label swap
In the case of experiments where label swap is utilized, the user should declare the swap by pressing Label swap options... as shown on the figure. Then, from within the popup window titled Label Swap Assignment, the user should specify the biological and technical replicates involved as well as the labels swapped and press the Add button. The list on the top-right shows the relevant raw files and the list at the bottom the declared label swaps.-

Advanced Options (continued): Functional Enrichment analysis
ProteoSign applies a functional enrichment analysis for all differentially expressed proteins. Functional Enrichment is enabled by default, requiring the experiment's target organism name (or scientific name) to be typed into the respective text box. A list of suggestions will appear as the user starts typing in the box to help in submitting valid values.-

Statistical analysis wait page
Here the user waits for the software to finish the statistical analysis, while presented with current Nature Methods articles hyperlinks. When the analysis is finished, the user is navigated automatically to the next page (see below).
Statistical analysis results preview page
Here the user can preview the analysis output in the form of representative key data plots. The button Next takes the user to the final page.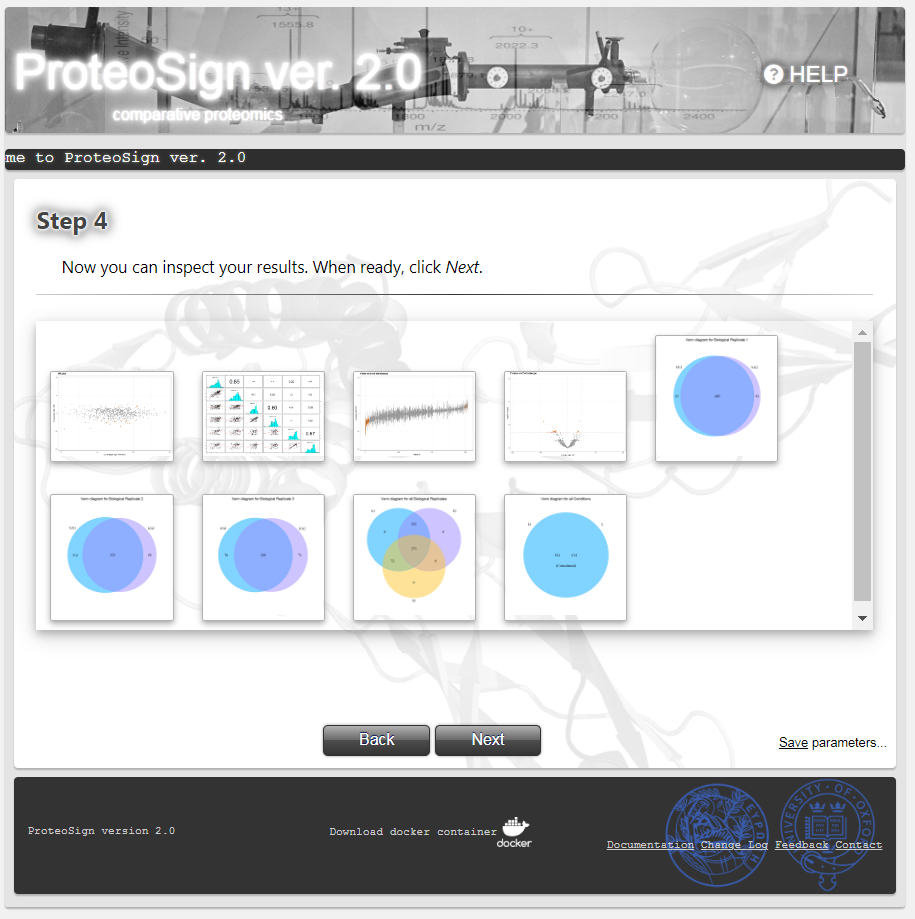
Final page
Here the user can click on the proteosign.zip hyperlink to download the entire software output, comprising the aforementioned data plots, other diagnostic plots and various data tables in the form of text files (see below). Also, they can preview the results of the functional enrichment analysis in the form of a table. Each row corresponds to a protein function, double clicking on a function redirects the user to a web page with more information. Since the enrichment analysis is applies to each pair of conditions compared, the user can choose which condition-pair respective analysis to preview by selecting it from the drop down list.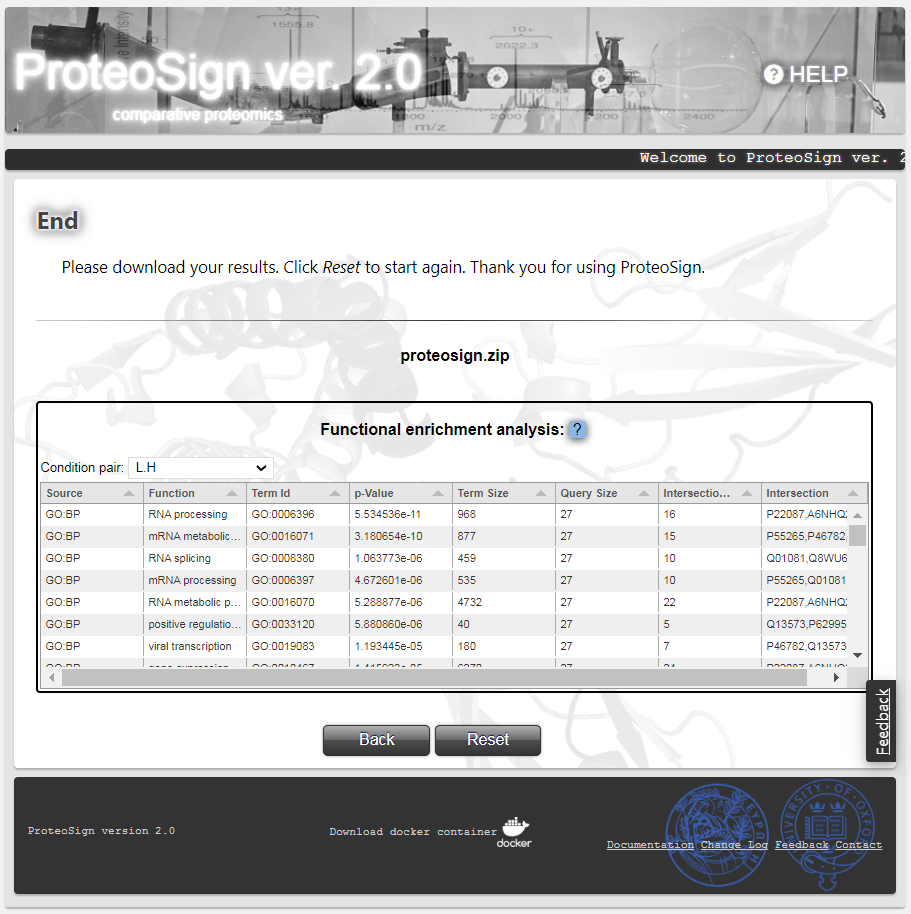
Sofware output files
The figure on the right shows the output files generated for the demo data set used throughout this Help page. The PDF files contain the aforementioned plots. For each of the text files, a brief description is provided below.
Log file
This file is generated by the core statistical analysis R script and can be used by the software authors for troubleshooting in problematic cases.
condition-i vs condition-j file
This table constitutes part of the core output of the statistical analysis software (LIMMA). For each protein, it shows:
Column A: the average log2 intensity across conditions and replicates.
Column Coef: the estimate of the log2-fold-change.
Column t: the moderated t-statistic.
Column p.value: the raw p-value corresponding to the t-statistic.
Column p.value.adj: the adjusted p-value.
Column F: the moderated F-statistic.
Column F.p.value: the p-value corresponding to the F-statistic.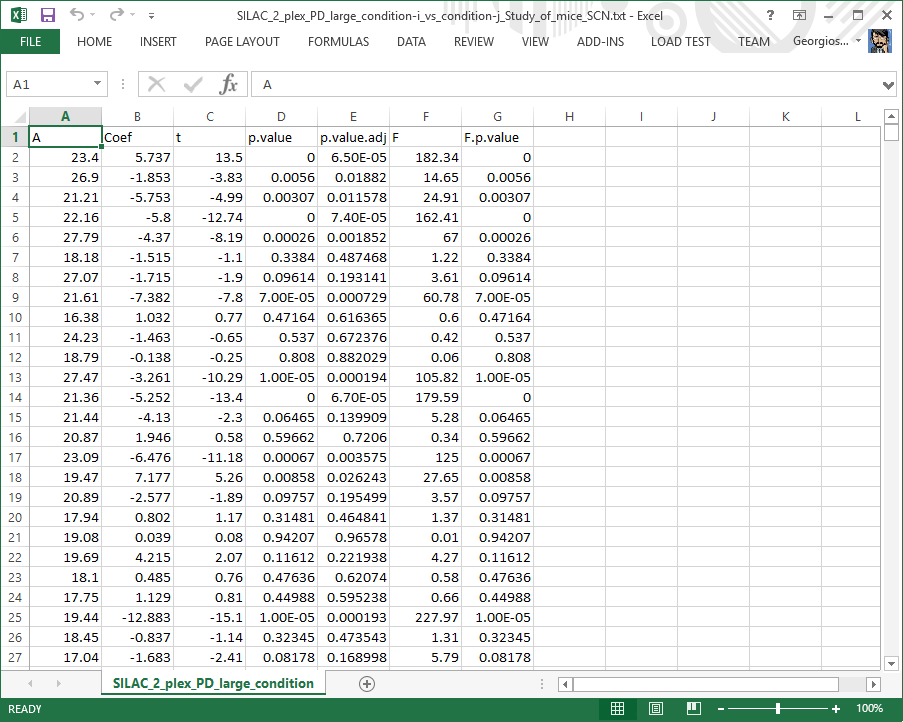
Blocking variable file
Indicates the technical replicates in the design matrix file (described below). This file is for diagnostic purposes only.
Design matrix file
Table showing the contents of the design matrix. This file is for diagnostic purposes only.
Contrasts matrix file
Specifies which comparisons between the linear model coefficients are of interest. This file is for diagnostic purposes only.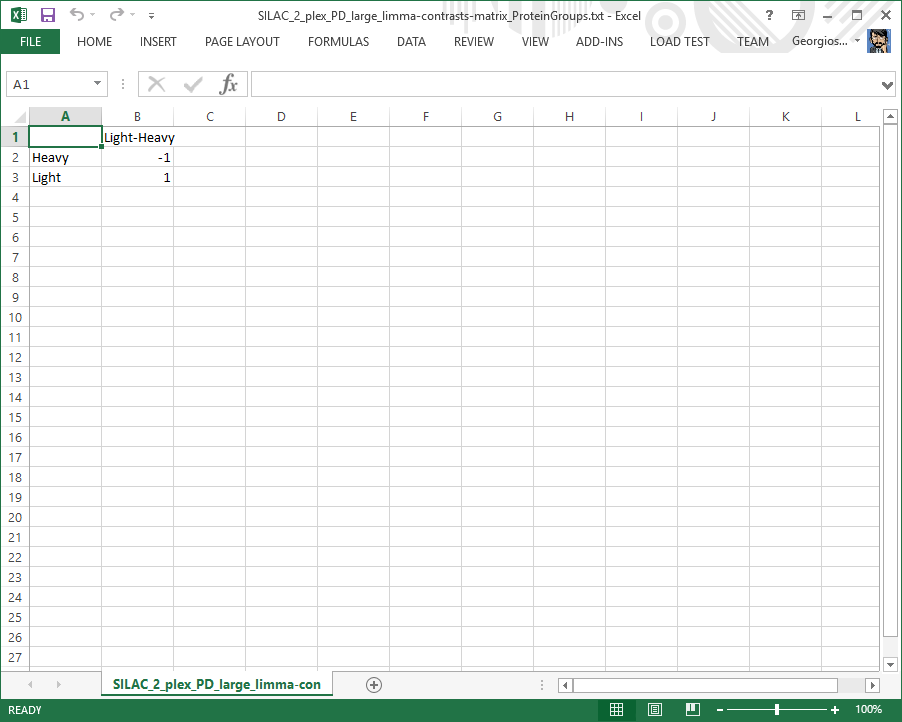
Quantified proteins list file
Table listing the proteins quantified in each biological replicate. Can be used to construct a Venn diagram.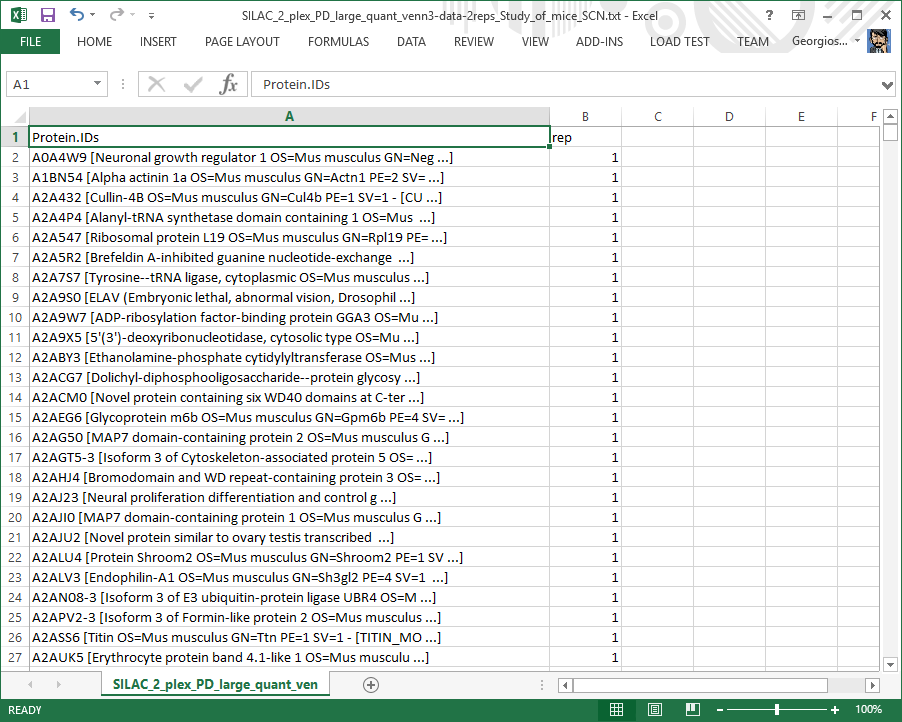
LIMMA input file
Table showing the pre-processed data that were subjected to log-transformation and quantile-normalization before being sent for analysis to the core statistics software (LIMMA). This file is for diagnostic purposes only.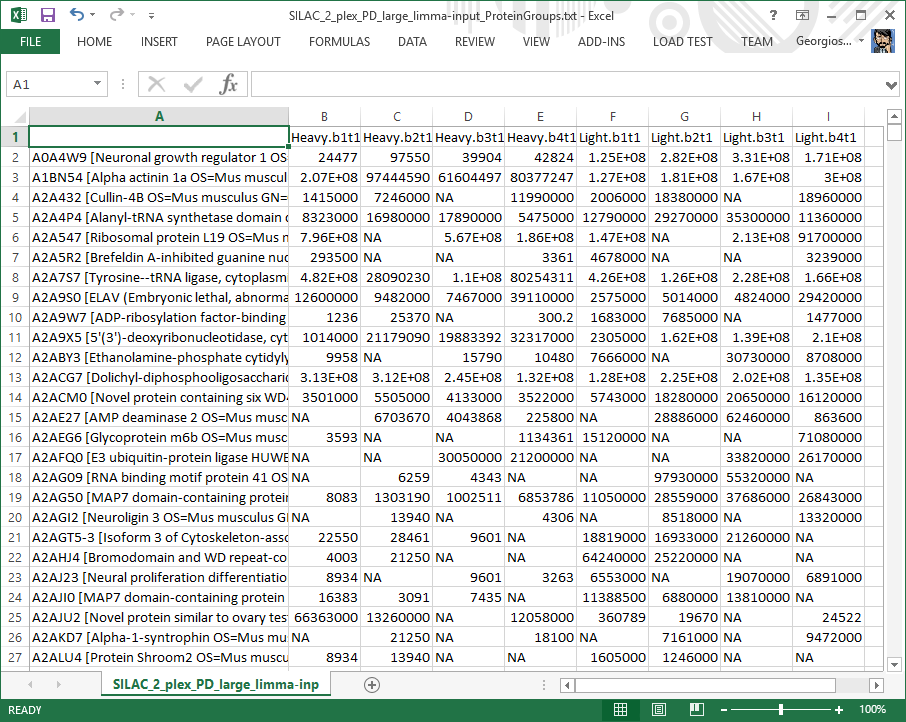
LIMMA early input file
Table showing an early version of the data that were sent for analysis to the core statistics software (LIMMA). This file is for diagnostic purposes only.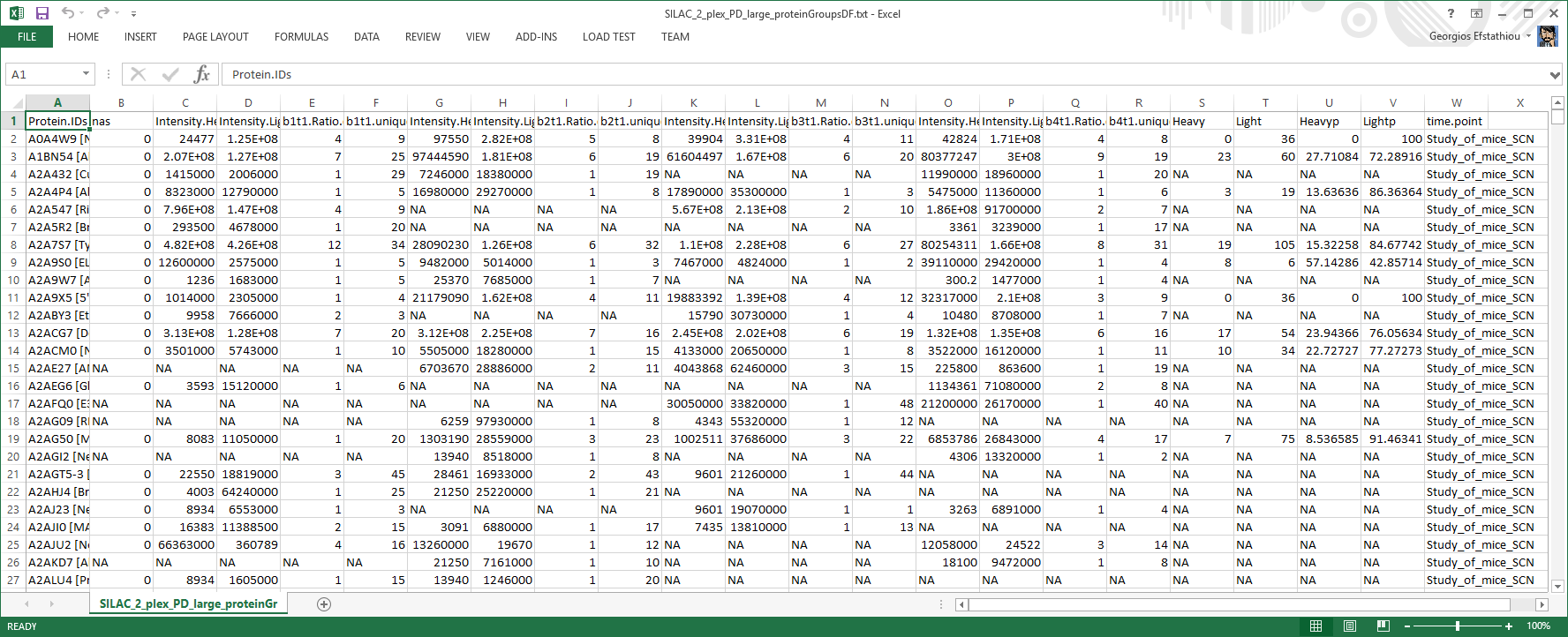
Identified proteins list file
Table listing the proteins identified in each biological replicate. Can be used to construct a Venn diagram.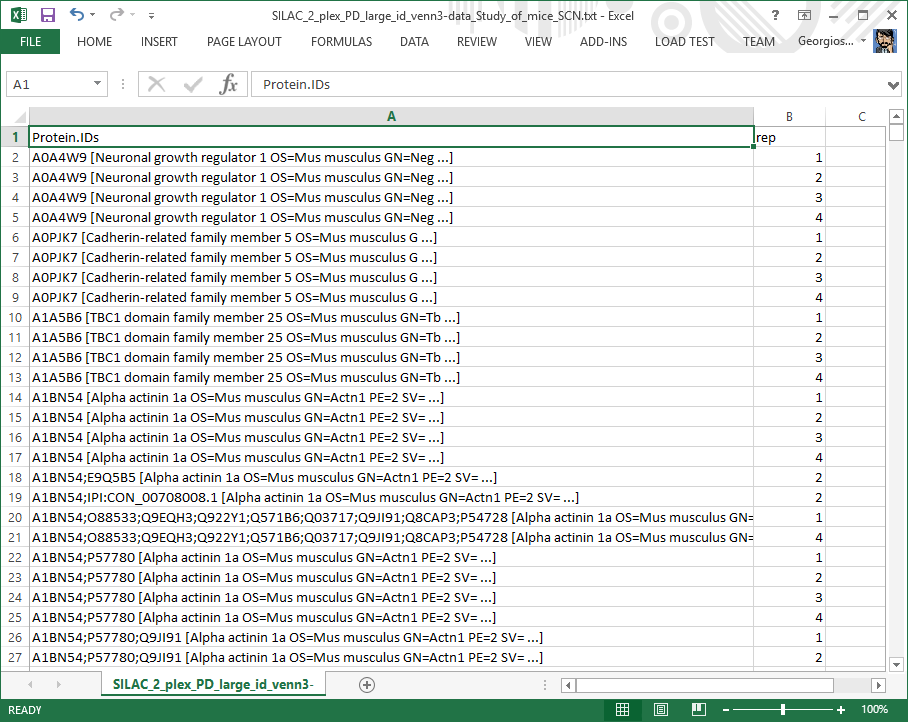
Results file
The statistical analysis main output file. For each protein, information about the expression ratio between conditions and its significance level are given.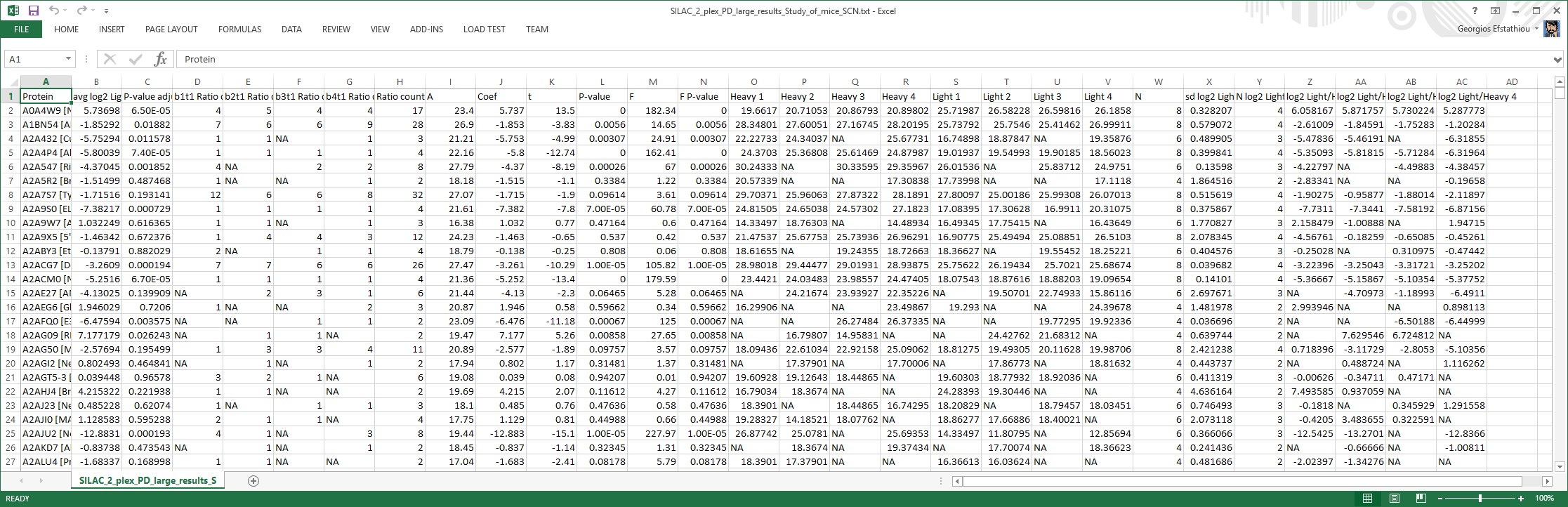
Top results file
A trimmed version of the aforementioned results file comprising only the statistically significant results (differentially expressed proteins).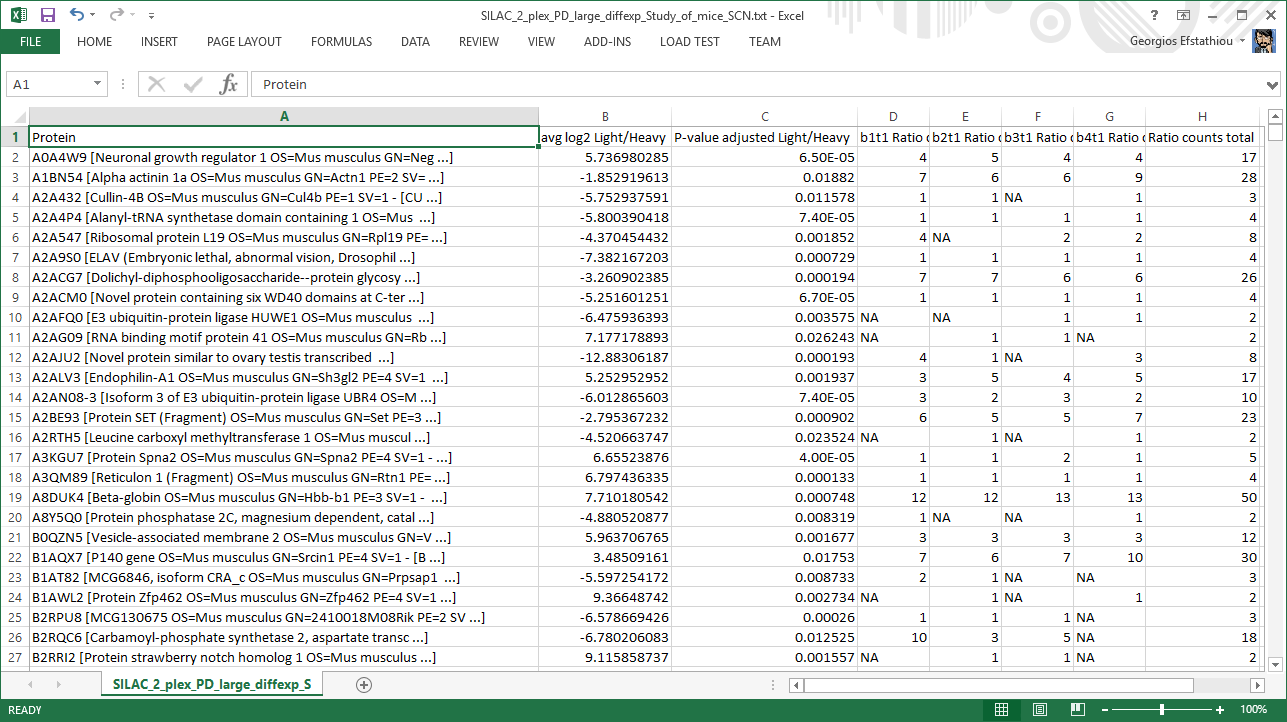
Plot_Generator.R file
An R script that produces all plots (getting the pre-computed data from the file Plot_Generator.RData contained in the same folder) so that the user can easily modify them.
Pre-normalization intensities PDF file
Box plots of log2 protein intensities before quantile normalization for each replicate and condition.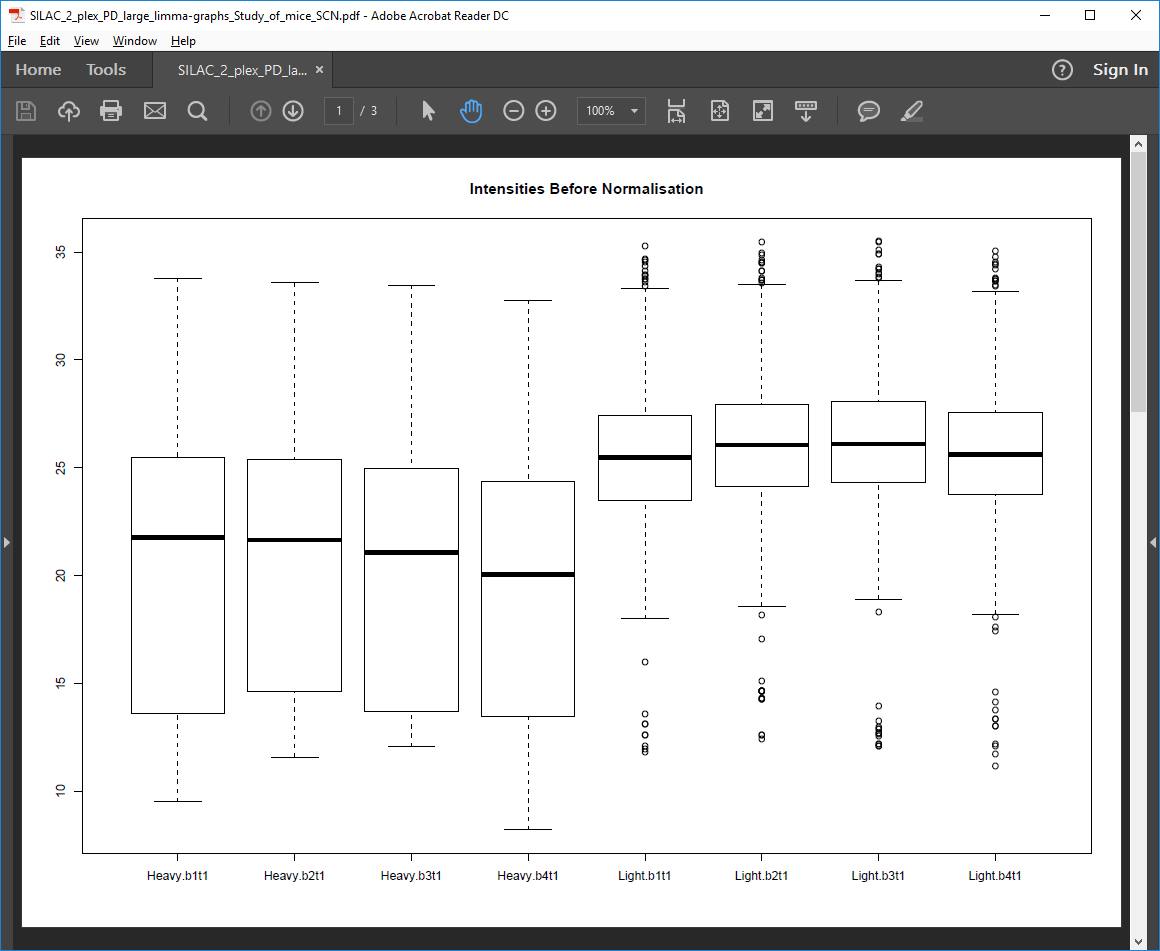
Post-normalization intensities PDF file
Box plots of log2 protein intensities after quantile normalization for each replicate and condition.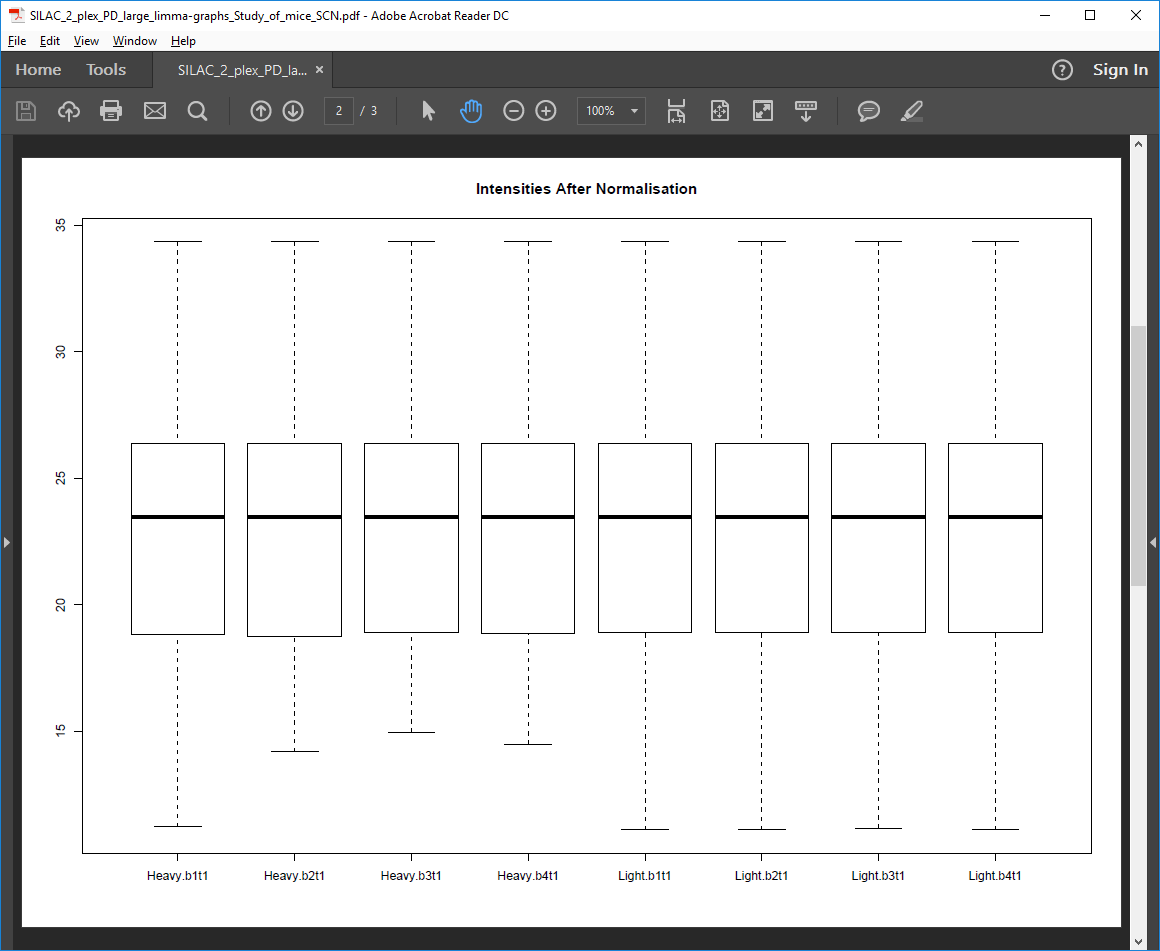
Log2-fold change histogram PDF file
Histogram of Log2 protein intensity ratio.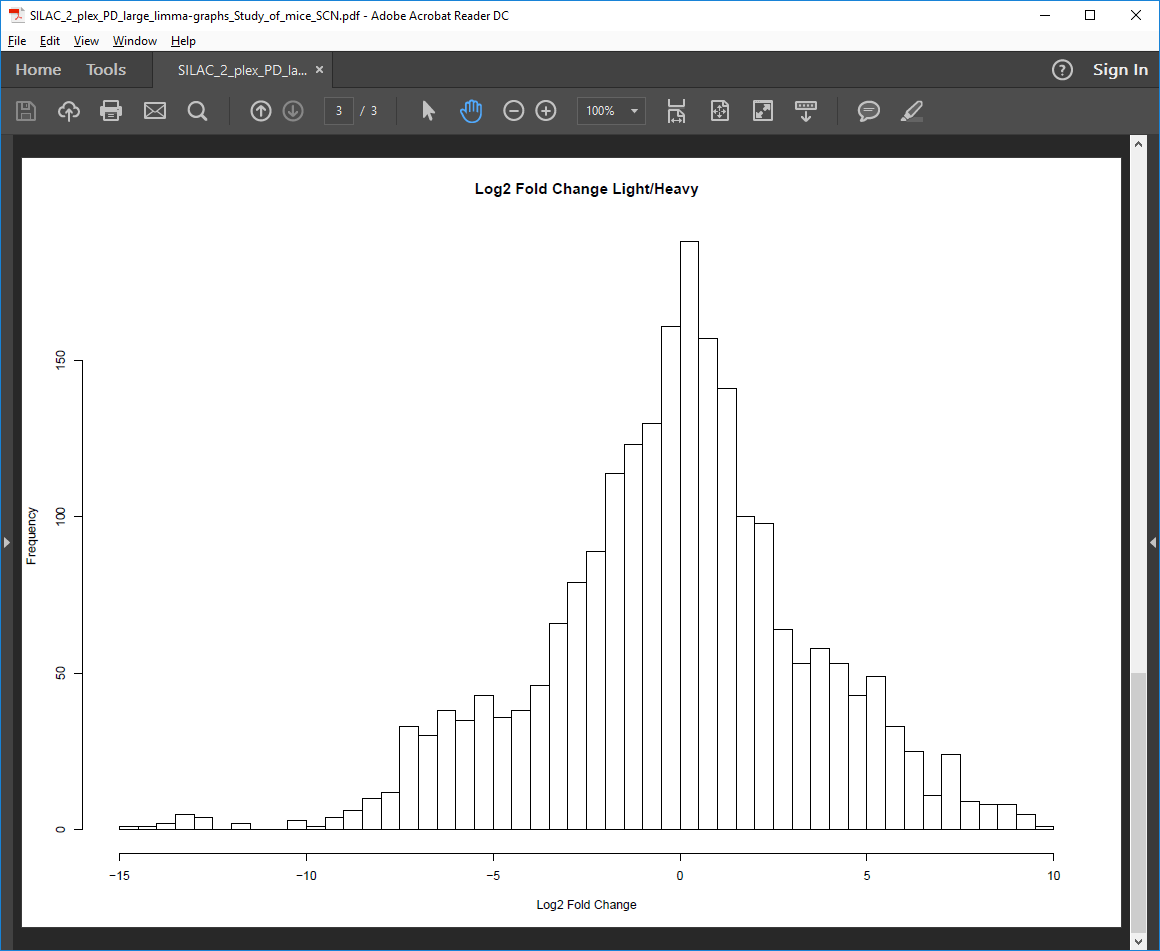
MA plot PDF file
Scatter plot of average log2 protein intensity ratio against average log2 intensity (also known as MA plot).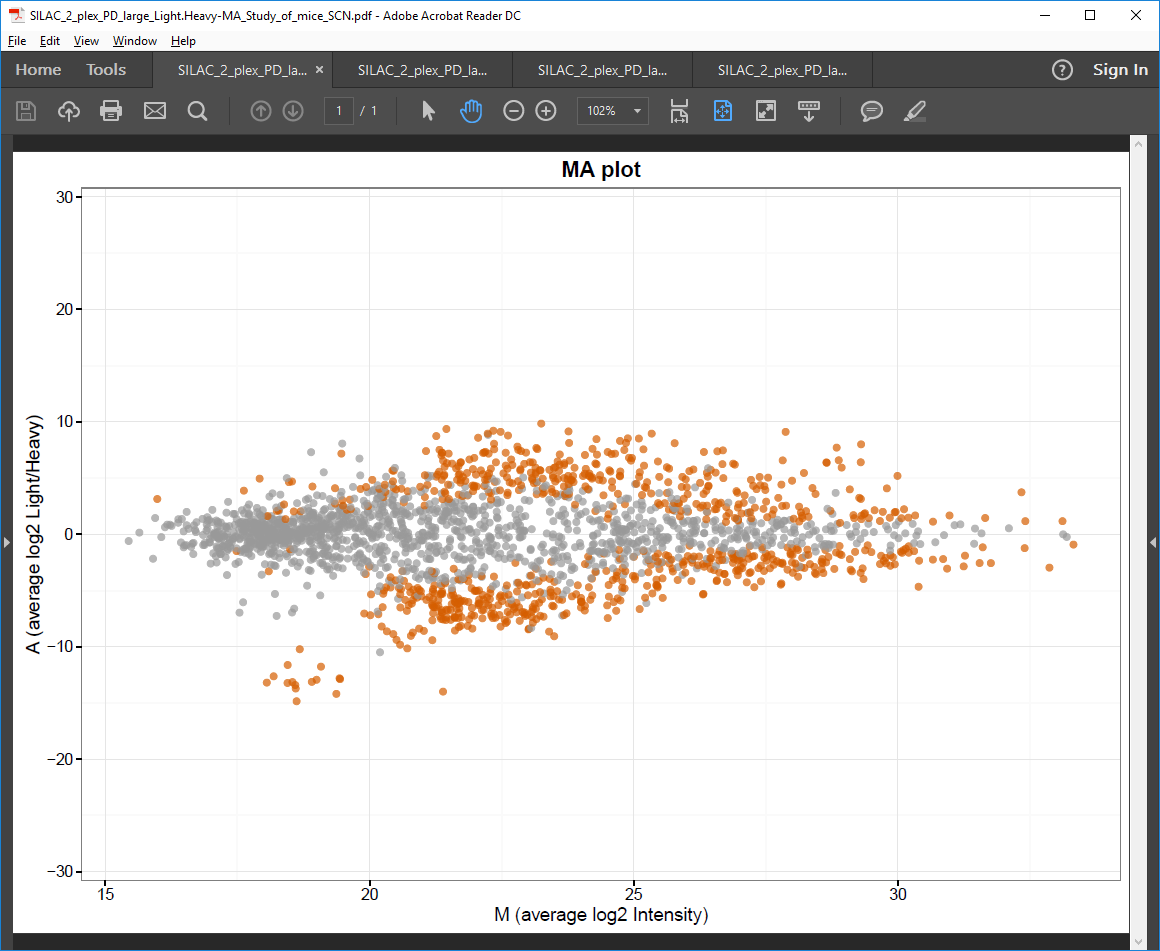
Intensities scatter plot matrix PDF file
Scatter plots and linear regression lines, histograms, and R-squared values for each combination of replicate log2 protein intensity ratio.
Value-ordered fold change PDF file
Plot of Protein number (ID) against log2 intensity ratio.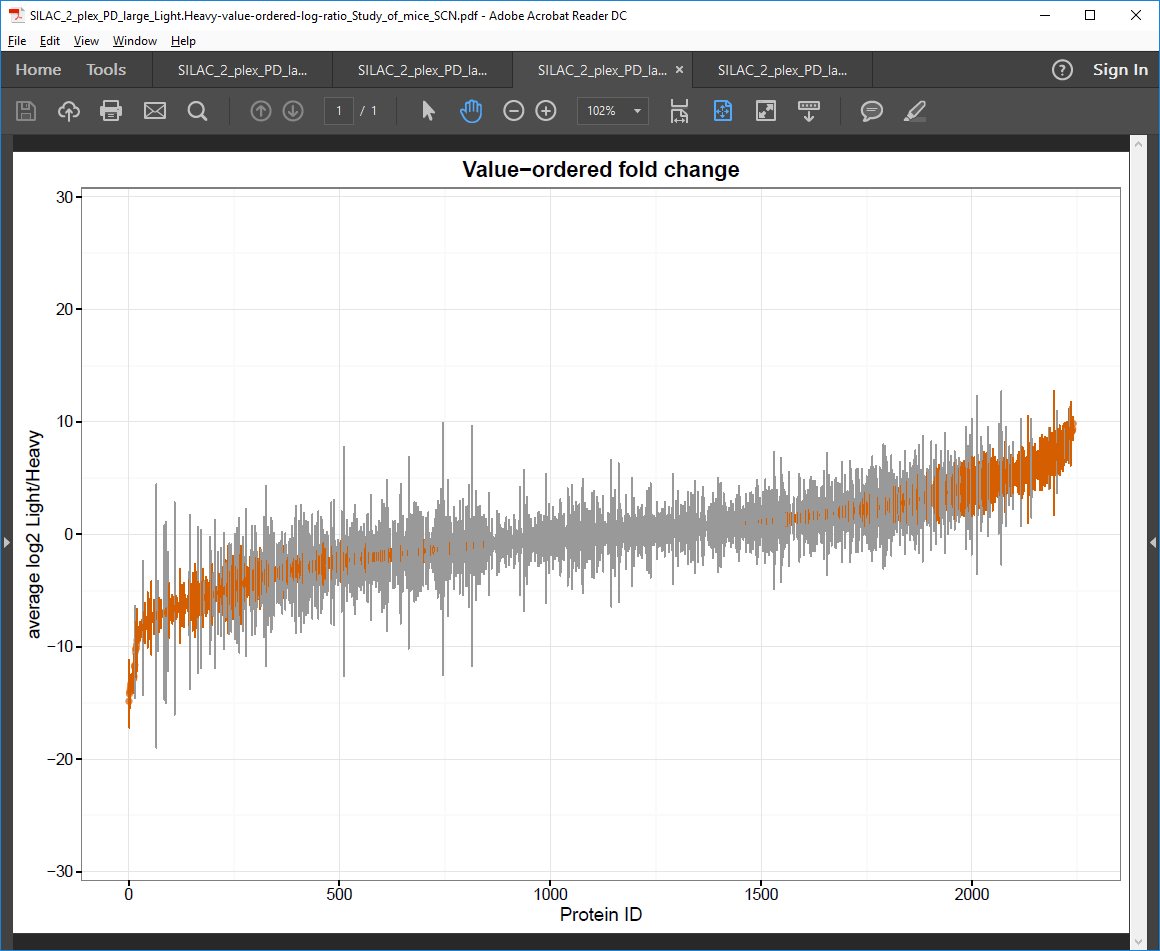
Volcano plot PDF file
Plot of average log2 protein intensity ratio against -log10 p-value (also known as volcano plot) .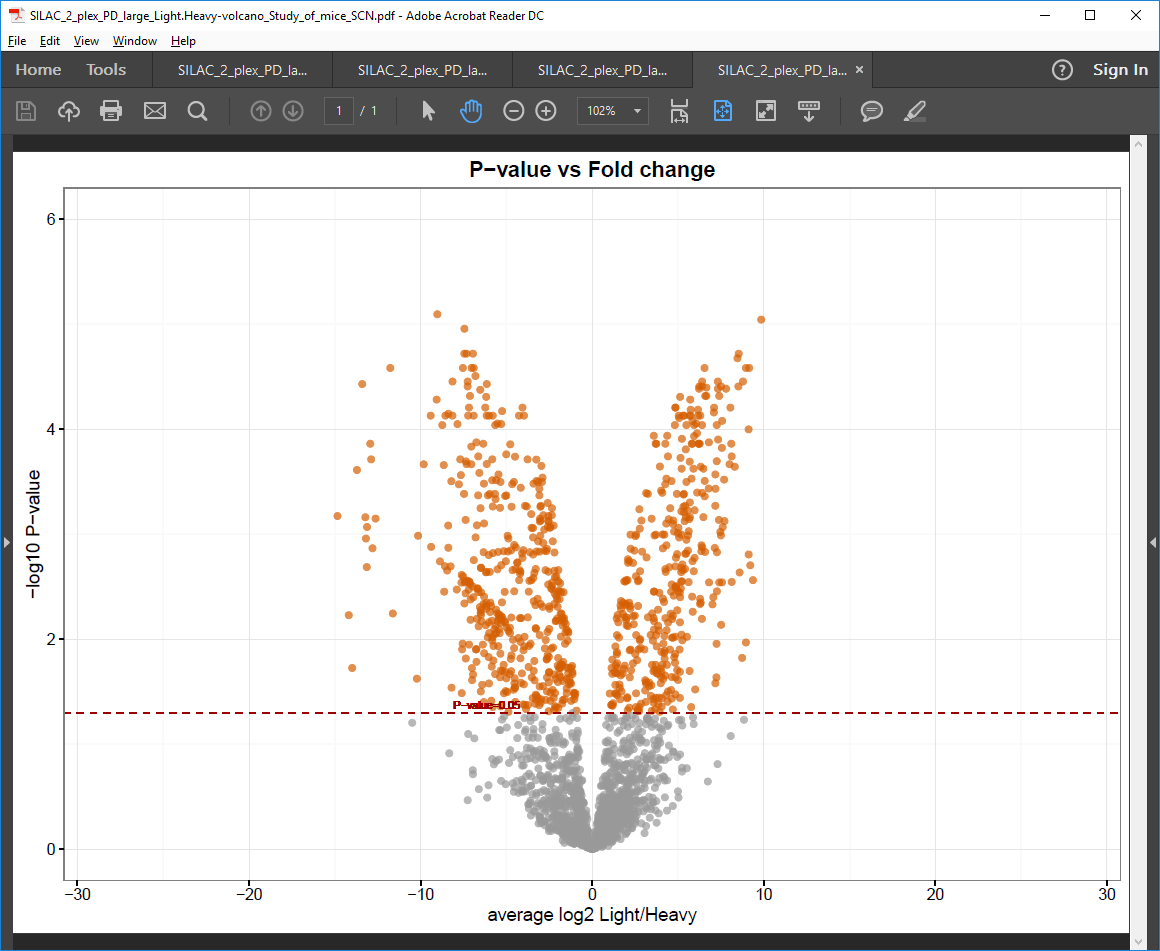
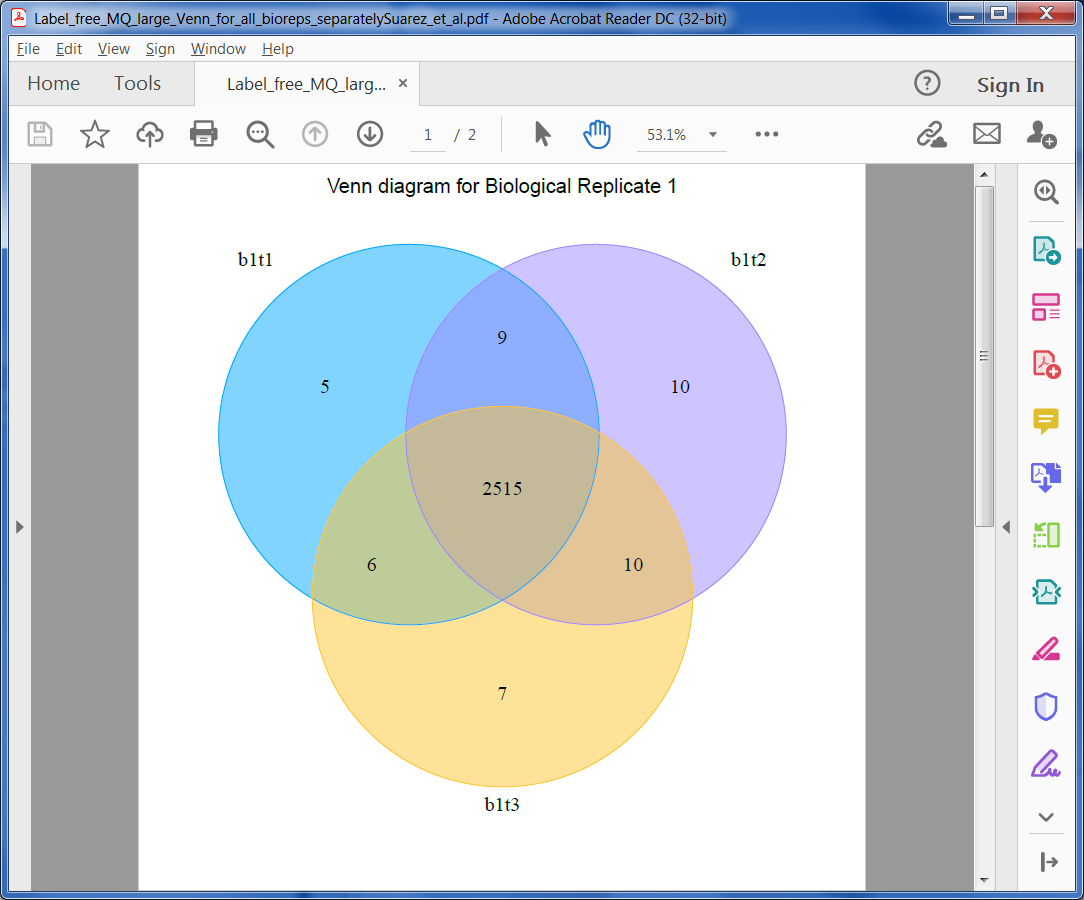
Venn Diagrams
Venn Diagrams help in evluating the reproducibility of the experiment. ProteoSign creates 3 PDF files containg Venn diagrams. One showing the amount of quantified proteins accross the experiment's conditions, one accross its biological replicates and one across the technical replicates of each biological replicate.